
 |
More on full text searching | Sunday, 28 March 2010 |
My goal is just experimentation initially, but also to aid in my daily work. I normally use 'crtags' (part of the CRiSP distro), which does syntax analysis to create a cross reference file. This is fine but sometimes you want something, and it may be in a text file or in a comment.
Although crtags can index plain text files, it was never optimised for this scenario (crtags is optimised to quickly find symbol definitions. and include data about storage type and declarations; the overhead of this, although small, can dwarf the index when the names are small).
In experimenting with the Perl code, there are trade offs. Indexing 200MB of files resulted in nearly 1GB of RAM usage. By optimising the memory usage, this is down to around 250MB - but attempts to get this better will trade off cpu for memory, and there are aspects of Perl where doing this are painful. (Perl is great for hash data structures, but theres a cost in that each item is self describing and the overheads involved are difficult to optimise against).
I rewrote the code in C to see how this would compare. The results are encouraging - 3x cpu performance and less memory usage (about 170MB vs 250MB for Perl). Theres a lot more we can try in C, but this looks to be in the right ballpark. (Some of my source files are .tar.gz files with executables in there and these are not being skipped, e.g. Windows .EXE inside a .tar.gz file).
The next step is to create the thing in a daemon mode - where it can run continuously looking for updates, but the memory usage - keeping the entire index in memory is not attractive, without some form of intelligent caching/paging.
| |
Full text searching and other stuff | Tuesday, 23 March 2010 |
CRiSP already supports tagging and full xref facility.
This is built on a suite of speedy parsers suitable for each language.
But I have always been interested in having a "context grep" tool - bit like Google for files. With grep you can easily search a tree for a pattern, e.g.
$ grep -R pattern dir
Thats great - its normally instantaneous for moderate amounts of data, especially if the data is in the cache. (The second time it will be; now that a small PC is one with 4GB RAM, its rare to be grepping more data than will fit in your buffer cache, unless you have lots of copies of source code, e.g. multiple linux kernerls).
In which case, a context sensitive indexing tools, like crtags (or ctags) is better, because you only read an index file which is teeny compared to the real files.
But, what if you want to do a google search:
...Find all files which have XYZ and ABC and APPLE in the file...
Think about it. Grep wont help. Grep *might* help if those three words are on the same line but its painful, e.g.
$ egrep "XYZ|ABC|APPLE" ...but thats no good if XYZ is on one line and ABC on another etc.
In google, (or Bing, or Yahoo), we just do:
Google: xyz abc appleor
Google: +xyz +abc apple -microsoft
So, I spent a couple of hours writing a full text indexer. I had written one before - it was no good, and machines were too slow to work with my bad algorithms. Results were good, but not brilliant. A day later, I had it more in tune with what should happen, using a reverse lookup algorithm. Instead of listing all words in a file, we list all words in all files, and associate which files that word appears in.
It becomes apparent how Google got off the ground: the code is trivially easy, and lends itself to parallelism and huge globs of refinement. The easy bit is easy, the difficult bits are hard. For example:
- What to do with .gz, .bz2 files? (Answer: decompress and parse them)
- What about .tar files? or .tar.gz files?
- What about bitmap files (bmp, gif, jpeg)? And video? (Answer: if you dont ignore them, your index is full of interesting words like XXXXXXXXXXXXXXX or _________________ So you skip them.
- Ditto for executables or object files
The code is written in Perl. Its short and sweet. But then the problems begin. You want the indexer to be run continuously. Having created an index.gz file, you need to update it when files change - which means reading, parsing, updating and writing out the updates to the indexer. This is super expensive. (Almost cheaper to rebuild from scratch the index than to apply updates; not quite, but nearly).
Worse - perl lends itself to hashes-of-hashes and for a few hundred MB of source code files, the script can use in excess of a gig of RAM. A C implementation would be much more memory frugal, but that might not be enough
For people using MacOS or Windows with full desktop search, you need a background app that doesnt eat cpu, doesnt hog disk bandwidth, allows incremental updates, can use multiple cpus - unless the user is trying to do something.
So, before long you need to take the simple code, break it up, and remove the horrible CPU and RAM bottlenecks.
The results so far are encouraging - subsecond lookup times, but it would be better to keep the indexer running so it doesnt have to keep reloading/parsing the index file (which in turn implies hogging too much RAM).
I am contemplating enhancing the indexer (e.g. run continuously in the background, or look at better memory utilisation options) and/or integrate into CRiSP as a "nice to have".
There are many indexers out there - so, this is nothing new, but its hacker material - take a simple idea, implement it, then spend forever optimising it, and in the meantime, see if its useful as an add on to your personal environment or toolkit.
If people are interested in seeing the code, feel free to mail me. It is available on the crisp website in the tools/ dir, but will post a link if theres enough interest.
Perl is fine - but it shows its limitations when you need to micromanage memory.
| |
FCTerm and graphing | Sunday, 07 March 2010 |
It has been my only terminal emulator in all this time. Originally an experiment in learning X11 programming - it evolved into code which drives the CRiSP editor. (CRiSP took an alternate evolution which involved writing its own widget toolkit and being ported to other platforms, including Windows and MacOSX).
As the years have gone by, fcterm has been enhanced to include the following facilities:
- blinking
- infinite scrollback
- multiple terminal support
- map view of screens
- resistance to server restart (i.e. you wont lose sessions if X server needs to restart)
- speed - beating all competitors
- support for pty detaching/attaching
- highlighted search support (highlight all strings which match a pattern)
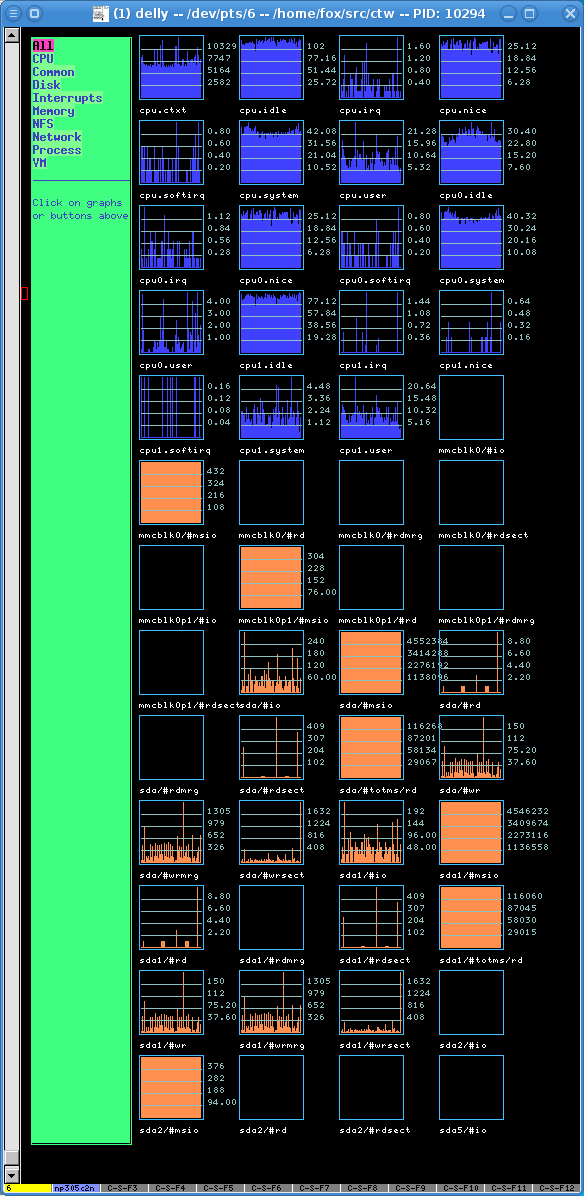
- samples/collect.pl
-
This can be used to collect samples of data from
the /proc filesystem - cpu, memory, vm, disk, etc.
This is stored in a CSV file (/tmp/collect.$USER).
By default this samples every 10s - about 2k per sample, so you may want to adjust the sampling if you intend to leave this running for long periods.
- samples/display.pl
-
Tool to display the graphs collected by collect.pl.
A menu bar is shown at the left, and you can click on the menu
entries to show different subsets of graphs (which update in
real time).
Click on a mini graph to zoom it to full window size.
display.pl understands the terminal being resized and adjusts appropriately.
All of this is done by escape sequences.
Most recently, fcterm was extended to include support for vector type drawing, similar to the tektronix emulation found in other terminal emulators. FCTerm doesnt support tektronix, because the tektronix mode is very outdated (e.g. no color support).
What FCTerm supports is Xlib like drawing via escape sequences. This means you can do some very interesting and impressive things.
One thing that interested me, after seeing so many panel widgets in systems like GNOME and KDE and iStat (tool for MacOSX), was looking at all the statistics available on a Linux system. You never know which stats will tell a story, and fcterm was modified to support graph drawing, along with a suite of perl tools and modules to collect and display the stats.
A simple perl tool collects the statistics, and another draws the collected data, in zoomable graphs.
Some screen shots of these graphs are available below.
(FCTerm is the name of the terminal emulator, but underlying fcterm is the CTW (color terminal widget) which implements the semantics of a terminal emulator)
Tools
FCTerm comes with a variety of tools to demonstrate the graphics mode.
Getting fcterm
You can get fcterm here:
ftp://crisp.dynalias.com/pub/release/website/tools/fcterm-current.tar.gz
Getting Help
You can see what escape sequences are supported from the
inbuilt command line. Type